

We are running a #KubernetesPlatforms series where we are sharing our experiences and thoughts on how to build Internal Kubernetes Platforms.
In the previous post, we saw what goes into offering a self-service experience and the benefits it brings to Developers and DevOps teams.
In this post, we will dive right into the first thing that a Kubernetes platform needs to take care of – Cluster Management.
All cloud providers make it very simple to create a Kubernetes cluster. So what’s the big deal?
The deal is this: When we are building a self-service Kubernetes platform, there are many questions that the platform owners need to answer on behalf of the organization and the platform users.
- Which Control Plane should we pick? Should we pick the ones offered by the cloud providers? Or something common that works across all cloud providers?
- What about on-premises clusters? Edge? How are we going to manage clusters there?
- How do we take care of cluster’s availability and scalability?
- What components should we bootstrap in the cluster by default? What are the popular ones?
- The platform needs to be able to connect to clusters running in many different cloud accounts and on-premise locations. What will the networking look like? If we keep the control plane access completely private will there be complexities?
- How will our clusters support running different types of workloads that may need specific infrastructure (eg: GPU instances)? How will we balance availability, performance and cost?
- What about updates? How will we safely roll out Kubernetes version updates? How will updates to bootstrapped components work?
We faced the same set of questions when we built Kubernetes platforms in the past. In this post, we will try to answer these questions.
The Control Plane
A Kubernetes cluster consists of two major components – the Control Plane and Worker Nodes. This documentation provides a good overview of the architecture.
Simply put, Control Plane is the brain or like a nerve center. It controls the entire cluster and maintains the state of the cluster. The worker nodes are where our containers run.
The first step in bringing up a Kubernetes Cluster is to provision the Control Plane. So, let’s look at it a bit deeper.
The control plane primarily comprises of three main components:
- api-server: This component exposes the Kubernetes APIs. When we use kubectl commands, they hit the api-server
- scheduler: This component is responsible for scheduling our containers. When we request a Pod to be created, the scheduler figures out in which node the pod needs to be created and manages the whole lifecycle post creation (such as moving the pod around, terminating)
- etcd: A key-value store that maintains the current state of the cluster. Essentially a database that stores the manifests that we provide (the YAMLs) and the current state of those manifests
As you can see now, the control plane is super critical for a Kubernetes cluster. For a production-grade cluster, the control plane needs to be Highly Available, Scalable, Secure with constant backups being taken for components such as etcd.
In addition, you also need to keep them updated (as new Kubernetes version gets released) along with keeping the underlying host (in which the control plane runs) secure.
For all these reasons, we highly recommend you choose a managed control plane – a managed service that provides a highly available control plane and is managed by the service provider.
As part of the platform operations, you should avoid managing the control plane unless you have very specific requirements that none of the managed service providers meet.
So which managed service provider to pick? That depends on a few parameters.
Multi Cloud
If your infrastructure is only in the public clouds, then it’s pretty straightforward. The major public cloud providers provide a managed control plane in the form of Amazon EKS, Azure AKS, and Google GKE.
All of them provide a fully managed service that offers a Highly Available and Scalable control plane. They are also available in most of the Regions making it easier for you to create clusters anywhere globally.
Hybrid Cloud
If your infrastructure comprises both public cloud and on-premise (and maybe the edge), then the decision making matrix becomes slightly complex. Broadly there are two choices:
- Extending cloud provider’s managed services to on-premises
- A third party service provider that works across public cloud, on-premises and the edge
In the first option, all the three major public cloud providers offer their managed services to work on-premises too in the form of Amazon EKS Anywhere, AKS on Azure Stack, and GKE on-prem.
You will have the same experience of managing the control plane and the APIs (to provision and manage control planes) will also be similar.
However, this option best works if you use only one public cloud provider along with your on-premises infrastructure as you can streamline using one service.
If you use multiple cloud providers, then this strategy will introduce more operational complexity for the platform operators.
And that’s when the second option makes more sense – to pick a common third-party managed service that works across any infrastructure be it public cloud, on-premise, or the edge.
You can pick a managed service provider like Rancher that seamlessly works across any infrastructure.
Irrespective of the service provider choice, it is recommended to pick a service that provides a fully managed, highly available, and scalable control plane.
Control Plane Access
When provisioning the Control Plane, one of the important aspects to consider is how it’s going to be accessed.
A control plane provides direct access to the resources running in the cluster and hence it is vital to secure the control plane.
Managed Services such as EKS, AKS, and GKE allow us to create control planes that have only “private endpoints”. This means that you can reach the control plane endpoints (such as the API server) only if you have private network connectivity to the VPC in which the cluster is provisioned.
This is something to consider during the initial design stages of the platform. Because, a platform, by design, would be expected to work across multiple cloud provider accounts and multiple regions.
The platform in itself could be deployed in a shared cloud account. And from that shared cloud account, it would be required to connect to clusters in various cloud accounts that the users onboard into the platform.
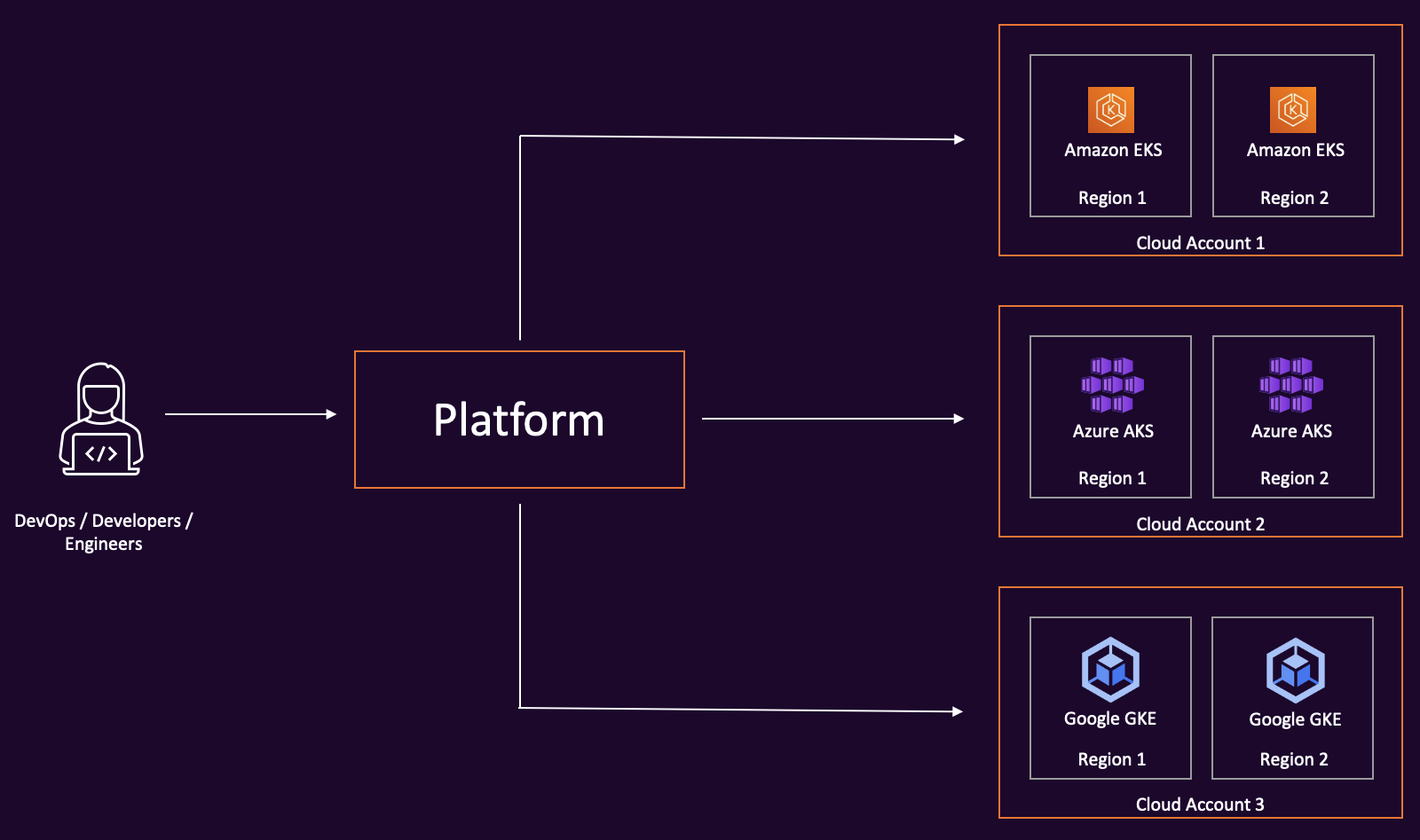
Hence it’s important to design the network connectivity that will be required for the platform to securely connect to all Kubernetes clusters it is expected to manage.
Node Pools / Node Groups
Node Pools as the name suggests are just a group of nodes with the same configuration. The worker nodes of a Kubernetes cluster can be organized as different Node Pools. Node Pools provide lots of operational flexibility for use cases as below.
- Some apps are CPU or Memory intensive ones and benefit from a certain type of Virtual Machine
- You have Machine Learning workloads and they need GPU based VMs. Only these pods needs to be run on GPU VMs and other pods should be run on regular CPU based VMs
- You would like to balance availability and cost by mixing both On-demand and Spot instances. You would like to schedule certain non-critical workloads on Spot and critical ones in On-demand Instances
- There is a new Kubernetes release and the worker nodes need to be updated. Before doing so, you would like to run some tests to see if there are any issues for your pods
There are many such use cases where Node Pools make cluster operations simpler.
The platform should provide the following capabilities with respect to Node Pools:
- Self-service creation of Node Pools both during and post creation of a cluster. Platform users will be required to create and dispose of Node Pools many times for the reasons mentioned above. Hence it is important to have a simple self-service experience to manage Node Pools.
- Flexibility to create Node Pools based on Arch (ARM, AMD, etc), GPU/CPU, On-demand/Spot, etc. Depending on your organization’s policies, platform owners can decide which architectures to support so that there is standardization of infrastructure as well.
- Dynamically resizing a Node Pool’s capacity including scale to zero. While Node Pools themselves will be set up with Auto Scaling (more on this in the next section), the ability to manually resize a Node Pool also needs to be provided. This helps during scenarios such as migration, upgrades.
High Availability & Scalability
Of course, it goes without saying that clusters provisioned through the platform need to be Highly Available and Scalable. The platform should automatically take care of the following:
- Creating a Highly Available Control Plane. EKS, by default, provides a Multi-AZ control plane. In GKE and AKS there are options to choose a Multi-AZ option when you create the control plane
- Node Pools created through the platform should also support Multi-AZ deployments
- Node Pools should be created with Cluster Autoscaler to dynamically scale the nodes based on resource requirements. Cluster Autoscaler primarily takes action during these scenarios:
- Dynamically add nodes when Pods cannot be scheduled due to lack of resources in the cluster
- When current nodes are under utilized and some pods can be moved around, then Cluster Autoscaler will terminate nodes resulting in better efficiencies
Note: Cluster Autoscaler does have its limitations in terms of how quickly it can scale up and down. There are newer projects coming up (such as Karpenter) that address some of these shortcomings.
Bootstrapping
This is a big responsibility that the platform needs to take on its shoulders and this is one of the areas where the platform adds value.
When clusters are provisioned through the platform, all the necessary components required to operate workloads in production need to be bootstrapped automatically.
The onus really is on the platform owner (in consultation with other stakeholders) to:
- Arrive at the list of components that needs to be bootstrapped in every cluster
- Picking the right choices for each component (eg: which ingress controller? Istio or Linkerd?)
- Making sure those components are rightly configured to meet your organization’s security, availability and scalability requirements
- Maintaining a compatibility matrix between the chosen components versions and Kubernetes versions
- Regularly update the components versions
Some of the components that typically need to be bootstrapped are:
- Ingress Controllers
- Service Mesh (Istio, Linkerd, etc.)
- cert-manager
- external-dns
- external-secrets
- Observability Shippers (agents as Daemonsets)
- Security and Governance policy enforcement tools (such as Calico, OPA)
- Various CSI drivers (such as Amazon EBS, Amazon EFS)
- Continuous Deployment tools such as ArgoCD
- Any custom operators that is written by the platform teams for certain specific automations (eg: auto creation of Service Accounts)
In addition to these components, the bootstrapping process should also take care of applying other best practices. For example, to avoid exhausting your VPC IPs, you can auto-configure clusters so that Pod IPs can use Non-RFC IP ranges (eg: through GKE Alias IPs and EKS CNI Custom Networking).
While the above list is not exhaustive and complete by any means, bootstrapping clusters as per your organization’s and teams’ requirements is a critical feature the platform should offer. This will add a lot of value to the users of the platform and also helps in standardizing how Kubernetes infrastructure is deployed across various teams.
Updates
Last, and definitely not the least, is about managing updates to the Cluster. This is a big one given the pace at which Kubernetes and its ecosystem are currently evolving. This definitely cannot be left to the users of the platform to self-manage. The platform should provide a seamless mechanism to update clusters and their components.
Broadly, these are the areas that would require regular updates:
- Control Plane
- Worker Nodes
- Various bootstrapped components
If you are using managed services such as Amazon EKS, the first is kind of taken care of and simplified. Whenever new versions are available, the managed service provider will make the update available after performing their validations. We can then trigger the update through respective APIs.
Most control plane updates are backward compatible with at least 1 earlier version that’s running on the worker nodes. Hence the control plane can be first updated followed by worker nodes.
- The worker nodes can be updated by leveraging node pools. You can launch newer node pools, gradually move workloads to them and retire the older ones.
- Managed service providers may offer simpler mechanisms to update worker nodes. For example, Amazon EKS offers Managed Node Groups that automates most of the process.
- If you are self managing the Node Pools then the update process may look like:
- Launching new nodes by adjusting Auto Scaling Group configurations
- Maintaining Availability Zone balance while launching nodes
- Draining the pods from the older nodes
- Performing updates either sequentially or in parallel
- Finally terminating the older nodes
The last thing to take care of is updating all the bootstrapped components in the cluster. The platform team needs to maintain a version compatibility matrix of all the bootstrapped components and roll out updates to them.
You may also be required to disable some cluster components before performing the updates if they could potentially affect the update process itself.
When performing the updates, you will also need to ensure sufficient IP address space is available in your VPC network as you will be launching additional nodes (up to double your actual capacity). The control plane upgrades also may need additional IP addresses for the new underlying hosts that may be launched. So, this needs to be planned ahead as well.
All in all, the entire update process needs to be automated by the platform. The platform should offer a 1-click update mechanism that takes care of updating the control plane, node pools, bootstrapped components with no downtime for the workloads running in the cluster.
Blue / Green Updates
An alternative strategy for performing these updates is to follow a Blue / Green strategy. Instead of performing updates on the existing cluster, bring up a new cluster with the latest versions of all components and gradually move workloads to this new cluster.
While this looks like additional work, this strategy is much simpler and can provide more confidence.
- You can test your workloads in the newer cluster in a test environment before actually performing the updates to production clusters
- When performing the updates in production environment, if something goes wrong, you always have the current cluster to fallback
- You can also gradually move workloads to the newer cluster as you gain confidence
Summary
That certainly was a lot of ground that we covered. Kubernetes cluster management is ops heavy and involves lots of moving parts. However, that’s where the value of the platform comes out. When the platform takes care of all the above heavy lifting then users of the platform can confidently deploy their workloads and focus on the business.
By providing a self-service capability for cluster creation and management, the platform enables the following:
- Standardize how clusters are provisioned across cloud providers and on-premise infrastructure
- Bootstrapping the cluster with all required infrastructure components that are approved as per an organization’s policies
- Ability for DevOps teams to centrally manage clusters across multiple regions and multiple cloud providers in a single place. Teams no longer need to login to different cloud provider consoles or use different APIs/CLIs/Tools for cluster management